|
|
||
|---|---|---|
| .idea | ||
| assets | ||
| blog/ds19991999 | ||
| csdn | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
| single_article.py | ||
| user.py | ||
README.md
CSDN 爬虫
主要功能:爬取 csdn 博客指定用户的所有博文并转换为 markdown 格式保存到本地。
下载脚本
git clone https://github.com/ds19991999/csdn-spider.git
cd csdn-spider
python3 -m pip install -r requirements.txt
# 测试
python3 test.py # 需要先配置登录 cookie
获取 cookie
登录 csdn 账号,进入:https://blog.csdn.net ,按 F12 调试网页,复制所有的 Request Headers,保存到cookie.txt文件中
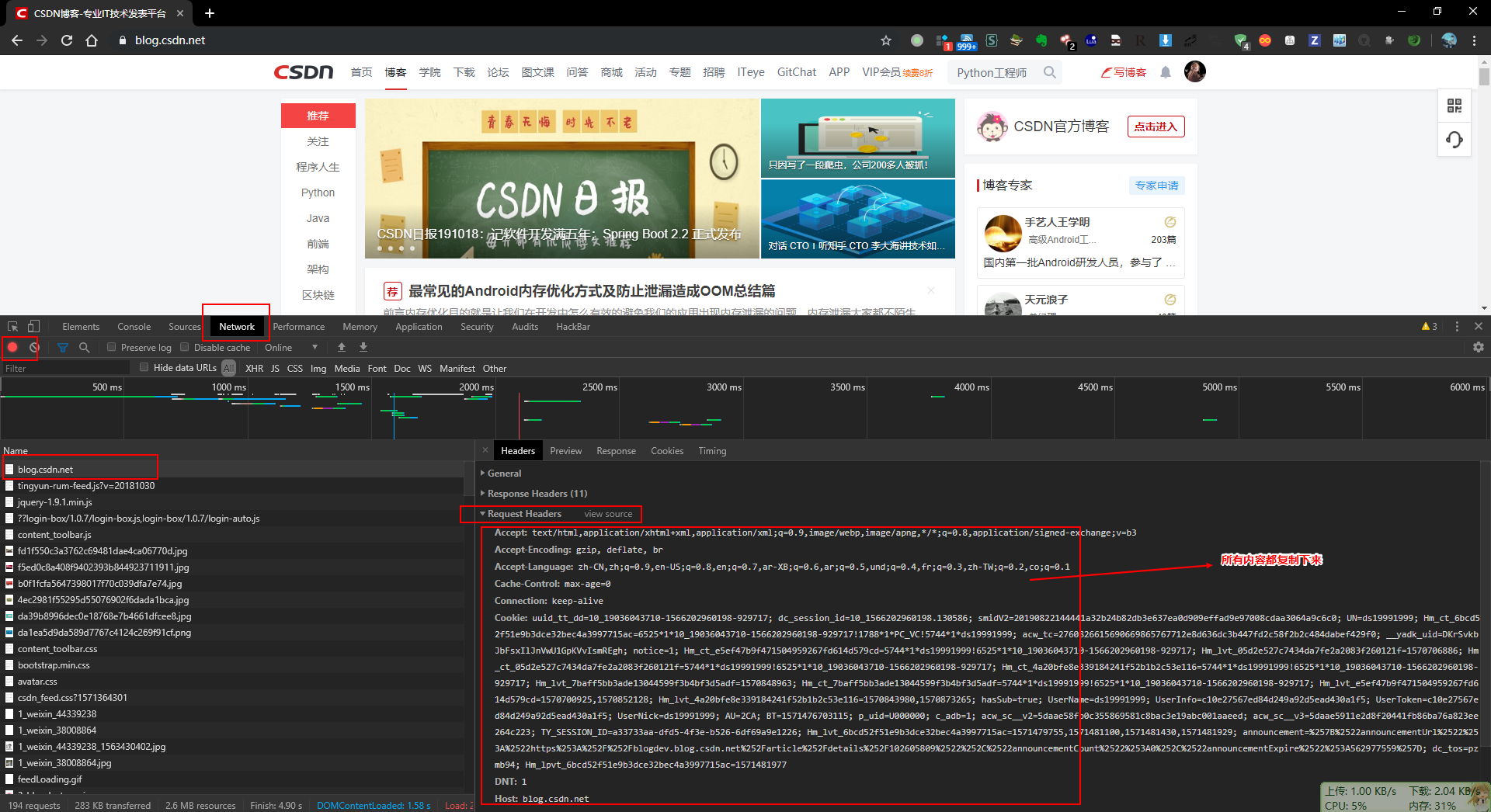
爬取用户全部博文
import csdn
csdn.spider("ds19991999", "cookie.txt")
# 参数 usernames: str, cookie_path:str, folder_name: str = "blog"
- 示例爬取博文效果: ds19991999 的博文
LICENSE

PS:随意写的爬虫脚本,佛系更新。